Model Details
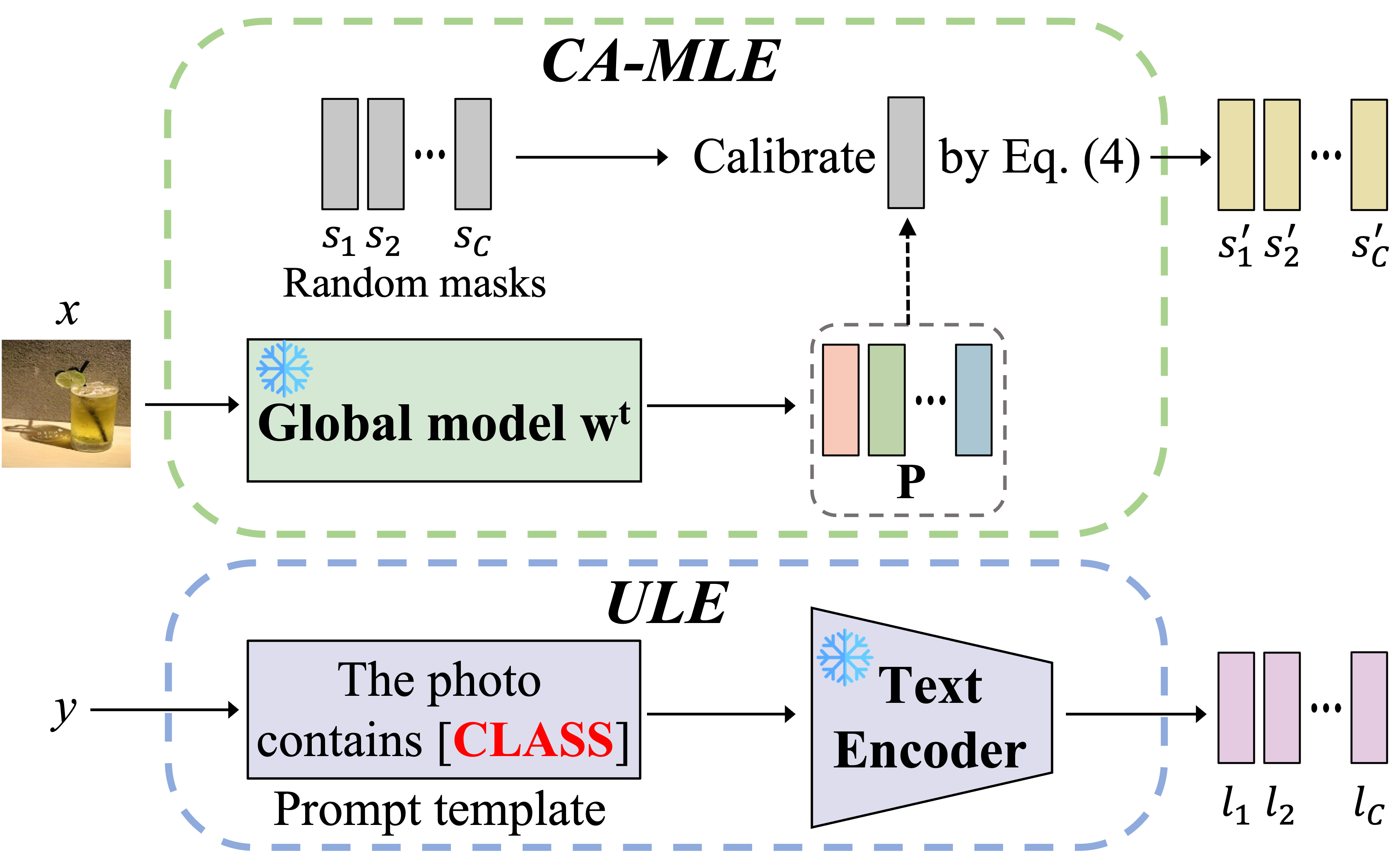
With the input image $x$ and label $y$, CA-MLE generates the prediction by global model $w^t$ and calibrates the state embeddings, while ULE advances the pre-trained label embeddings from CLIP for model aggregation purposes.
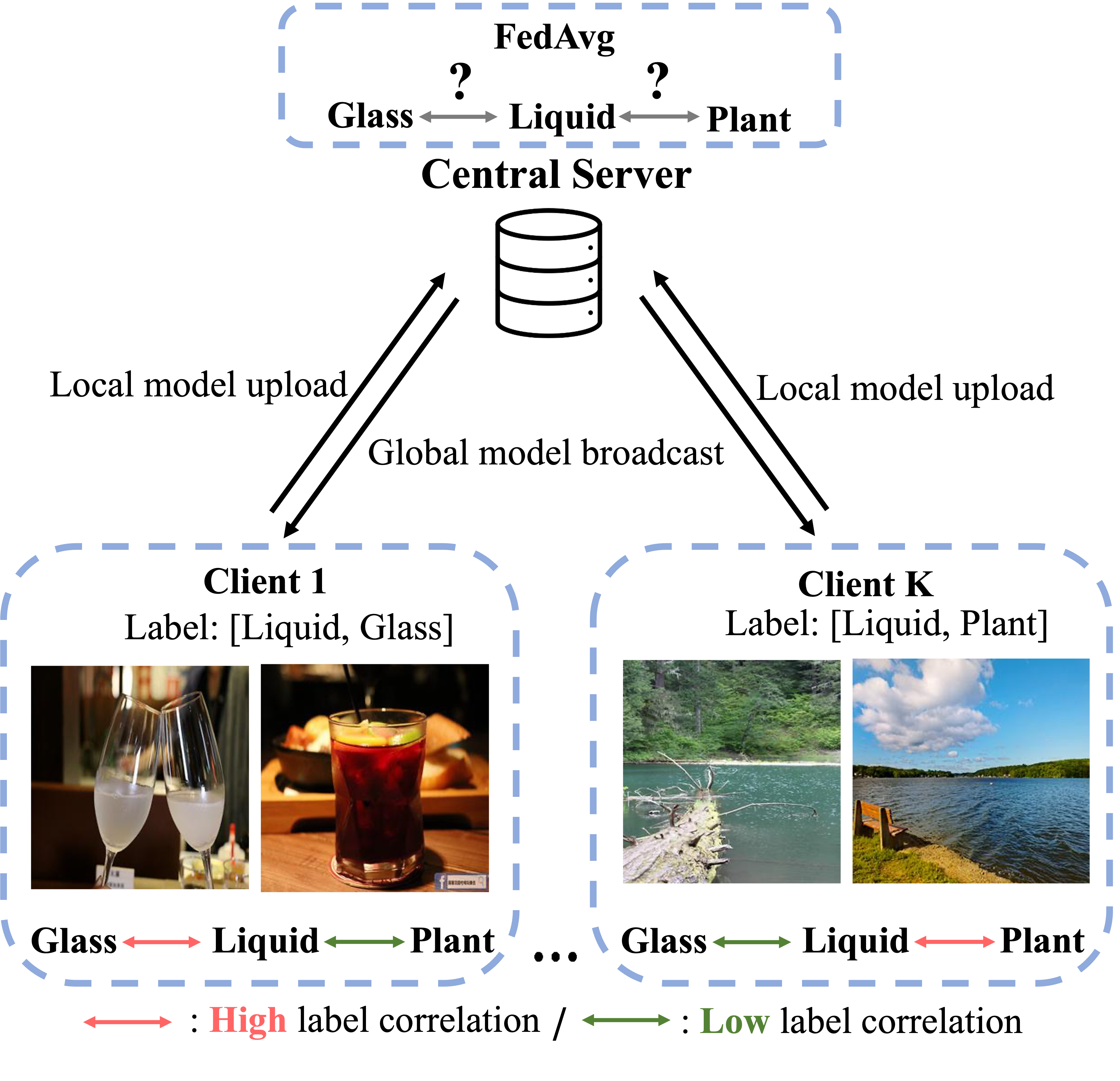
Challenges in multi-label federated learning. Since diverse label correlations can be observed across clients, aggregating local models might not be sufficiently generalizable.
Federated Learning (FL) is an emerging paradigm that enables multiple users to collaboratively train a robust model in a privacy-preserving manner without sharing their private data. Most existing approaches of FL only consider traditional single-label image classification, ignoring the impact when transferring the task to multi-label image classification. Nevertheless, it is still challenging for FL to deal with user heterogeneity in their local data distribution in the real-world FL scenario, and this issue becomes even more severe in multi-label image classification. Inspired by the recent success of Transformers in centralized settings, we propose a novel FL framework for multi-label classification. Since partial label correlation may be observed by local clients during training, direct aggregation of locally updated models would not produce satisfactory performances. Thus, we propose a novel FL framework of Language-Guided Transformer (FedLGT) to tackle this challenging task, which aims to exploit and transfer knowledge across different clients for learning a robust global model. Through extensive experiments on various multi-label datasets (e.g., FLAIR, MS-COCO, etc.), we show that our FedLGT is able to achieve satisfactory performance and outperforms standard FL techniques under multi-label FL scenarios.
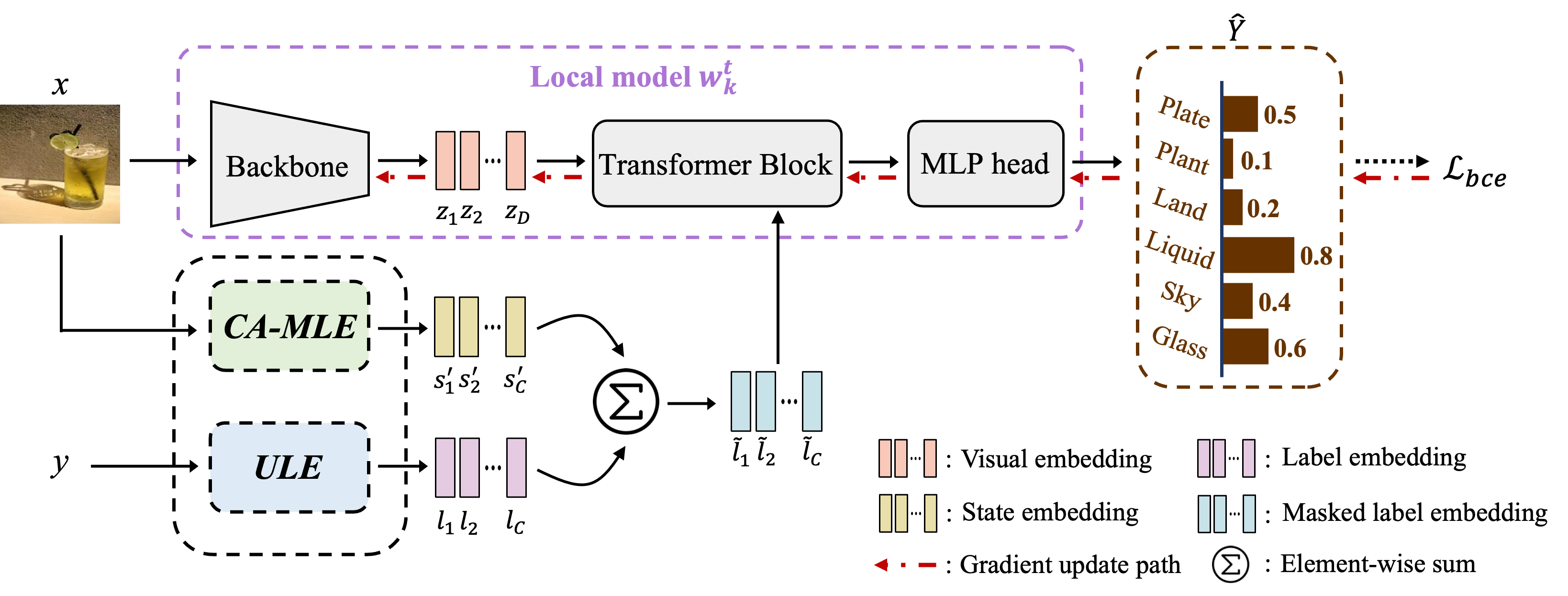
Overview of FedLGT. Given an image with multi-labels to predict, the global model from each communication round updates the local model with Client-Aware Masked Label Embedding (CA-MLE), which exploits partial label correlation observed at each client. In order to properly align local models for multi-label FL, universal label embeddings (ULE) are utilized in FedLGT. (Best viewed in color.)
With the input image $x$ and label $y$, CA-MLE generates the prediction by global model $w^t$ and calibrates the state embeddings, while ULE advances the pre-trained label embeddings from CLIP for model aggregation purposes.
We perform local model updates and global model aggregation in one communication round to achieve a federated learning process. The pseudo-code of our proposed framework is described in Algorithm 1 as follows.

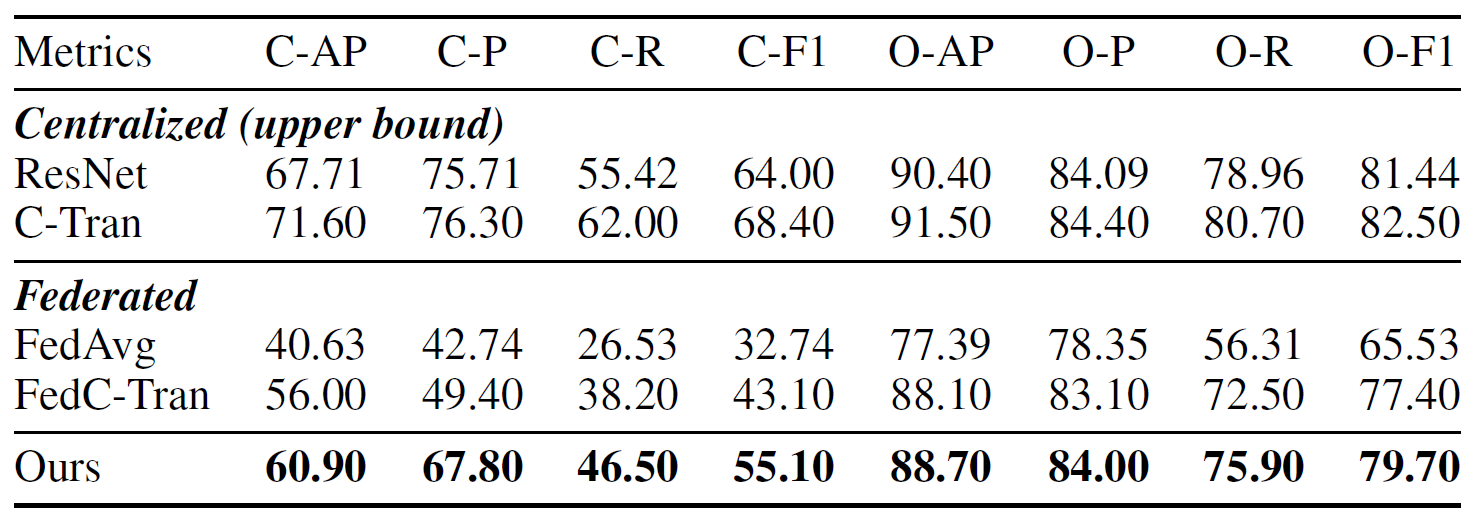
Table 1: Comparisons of coarse-grained multi-label classification task on FLAIR. Bold denotes the best result under FL setting.
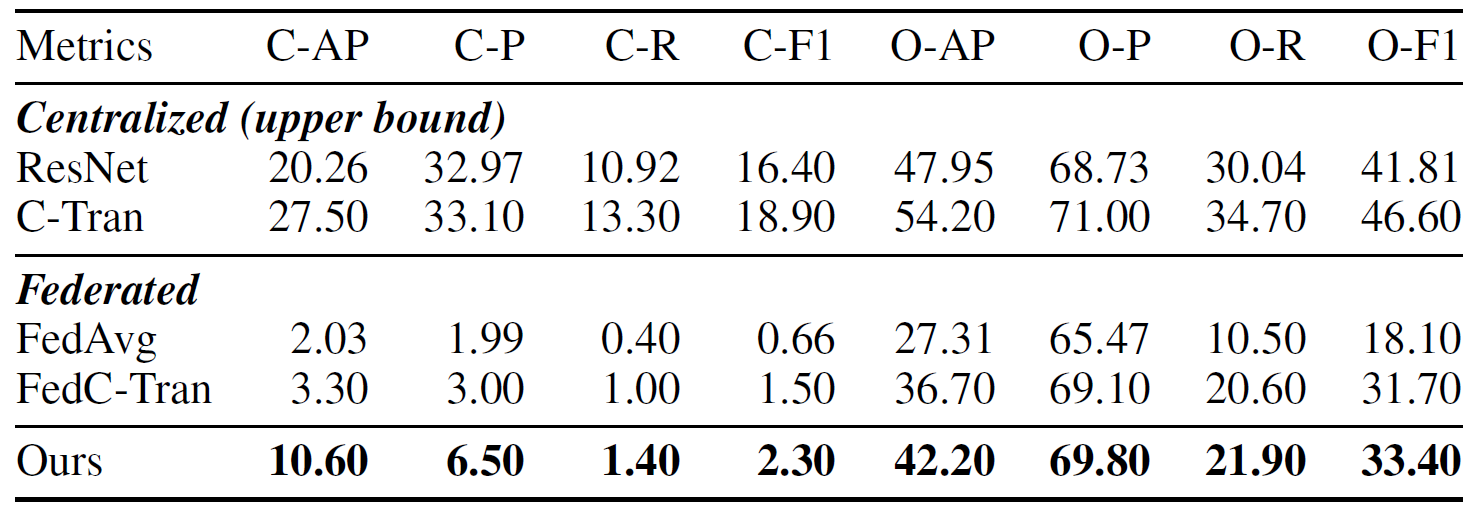
Table 2: Comparisons of fine-grained multi-label classification task on FLAIR. Bold denotes the best result under FL setting.
@inproceedings{liu2024fedlgt,
author = {I-Jieh Liu and Ci-Siang Lin and Fu-En Yang and Yu-Chiang Frank Wang},
title = {Language-Guided Transformer for Federated Multi-Label Classification},
booktitle = {AAAI},
year = {2024},
}