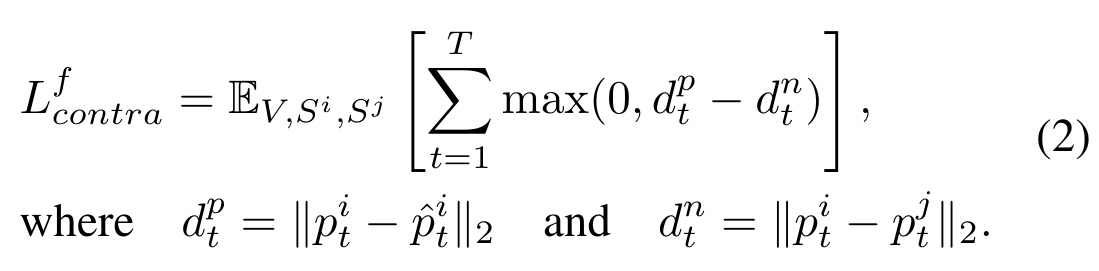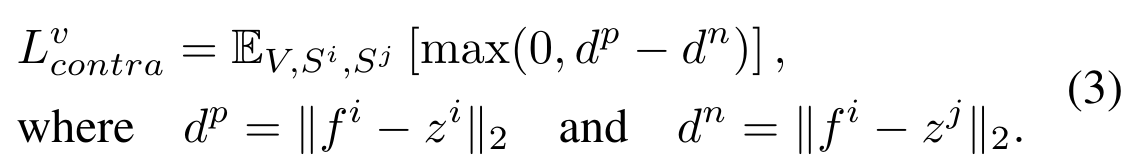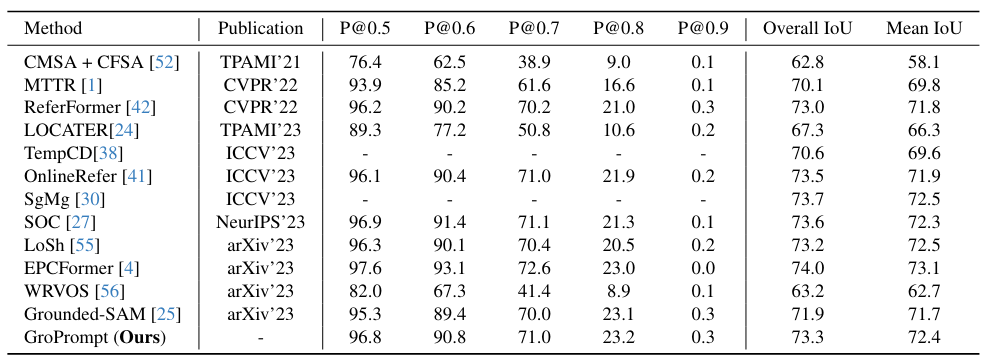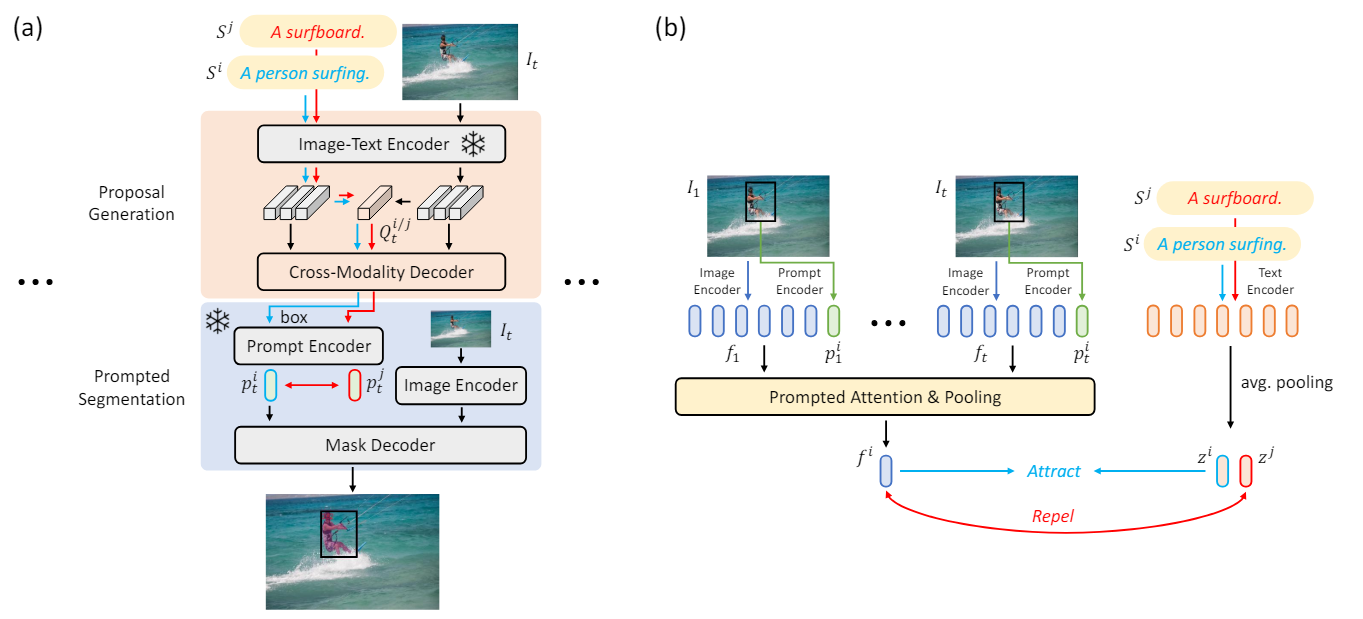
Text-Contrastive Prompt Learning.
Formally, in addition to the input sentence $S_i$, we forward another sentence $S^j$ through our GroPrompt framework to obtain the output proposal $B_t^j$ for another object at each frame. To perform contrastive learning, we leverage the prompt encoder from the foundation segmentation models to extract the prompt embeddings $p_t^i$, $p_t^j$, and $\hat{p}_t^i$ for the proposals $B_t^i$ and $B_t^j$ and the ground-truth bounding box $\hat{B}_t^i$, respectively. By taking $p_t^i$, $\hat{p}_t^i$, and $p_t^j$ as the anchor, positive, and negative sample, the frame-level triplet contrastive loss $L_{contra}^f$ would be computed as follows: